Microsoft's Orca2: A Revolutionary Step in Language Model Reasoning
Written on
Introduction to Orca2
In recent discussions, we've seen a surge of interest in Small Language Models (SLMs). Microsoft has unveiled the latest iteration of its flagship SLM, Orca2, which introduces a novel category known as Cautious Reasoners. This innovative model has set a new benchmark within the AI sector, outperforming models that are ten times its size in intricate reasoning tasks. The launch provides a comprehensive insight into Microsoft's AI strategy and the intricacies of Transformer learning. Today, we will explore how this new paradigm was developed.
For those interested in staying informed about the rapidly evolving AI landscape, my insights are often shared through my weekly newsletter, TheTechOasis. If you aspire to lead in the AI domain or simply wish to be well-prepared for future advancements, consider subscribing below:
Subscribe | TheTechOasis
The newsletter to stay ahead of the curve in AI
thetechoasis.beehiiv.com
The Emergence of Orca
When Microsoft introduced the initial version of Orca, it became the first open-source model that rivaled ChatGPT-3.5, prompting the AI industry to take smaller models seriously. The original Orca model has since evolved into a pivotal element of Microsoft's strategy, with speculation that the LLM powering Microsoft’s Copilots is not ChatGPT but Orca, primarily due to the exorbitant costs associated with managing models with over 100 billion parameters. Microsoft's philosophy is straightforward: If we can develop a model that offers 90% of the larger model's capabilities at a fraction of the cost, we will pursue that path.
You may be asking, how do we construct models significantly smaller than the major players while retaining most of their functionalities? The answer lies in the concept of distillation.
Understanding Distillation
The prevailing method for training small language models involves a process known as distillation, akin to an imitation game. As language models expand, they enhance their capabilities. Research from Google and Anthropic indicates that LLMs show no signs of plateauing in their learning potential. This leads researchers to consider an intriguing approach: instead of training a model to autonomously learn language, why not teach it to mimic another model?
This process, known as distillation, entails a student model imitating a teacher model by understanding the distribution of its responses. Essentially, the student learns to replicate the teacher’s outputs.
For instance, LLMs like ChatGPT generate a probability distribution over the next word. Given a sequence of text, they predict the most suitable word from their entire vocabulary. During distillation, the student model must not only replicate this output but also align its results with those of the teacher.
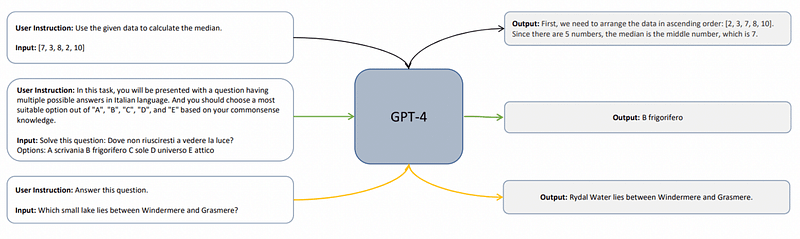
By collecting numerous examples from the teacher, the student can effectively learn to model language and imitate its instructor. However, there's a limitation: while the student may excel in style and fluency, it often struggles with reasoning tasks, akin to memorizing a math solution without understanding the underlying principles.
Introducing Orca's First Version
To address this limitation, Microsoft developed explanation tuning. Researchers prompted the teacher model to articulate its reasoning when generating the distillation dataset.
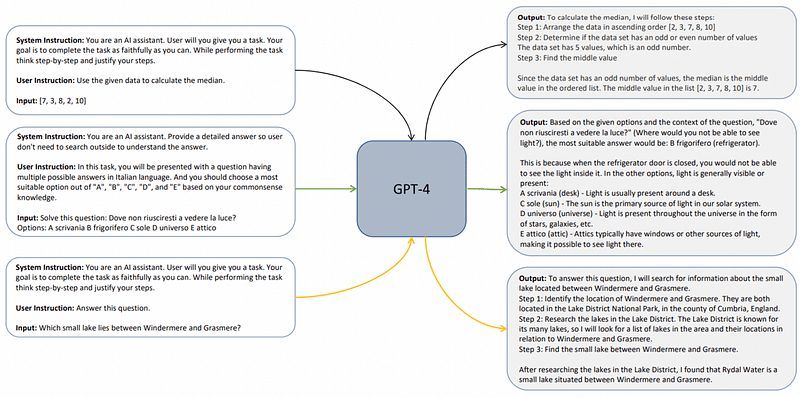
By requiring the teacher model (GPT-4) to detail its reasoning, Orca was able to surpass larger models like GPT-3.5 in virtually every dimension, despite being ten times smaller.
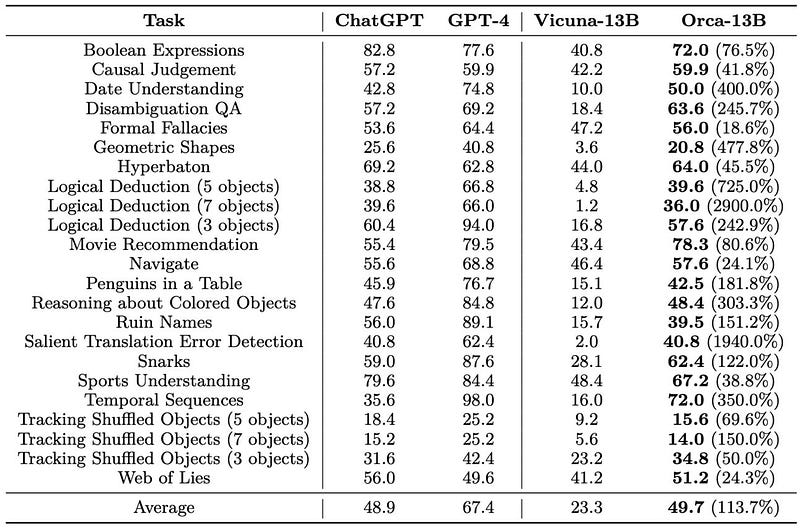
Nevertheless, researchers acknowledged that this process was still "sub-optimal," leading to the creation of Orca2, the cautious reasoner.
Advancements with Orca2
Although explanation tuning improved Orca’s ability to mimic GPT-4’s reasoning, it did not fully bridge the gap. Thus, researchers aimed to not only teach Orca to reason like GPT-4 but also to cultivate similar problem-solving approaches through prompt erasing.
This method involves masking the thought process, as LMs are significantly influenced by the prompts they receive. The chosen approach can determine whether they arrive at a correct or incorrect solution. To enhance the smaller model's capabilities, researchers needed to guide the student in selecting effective problem-solving strategies.
During the creation of the synthetic dataset from GPT-4 prompts, they instructed it to articulate its responses and apply the best problem-solving strategy for each task (e.g., step-by-step, explain-then-answer, direct answer).

This time, however, the researchers concealed the system instructions during training, compelling the model to independently deduce the appropriate strategy. As a result, students learned to navigate complex reasoning processes without explicit guidance.
Results and Implications
Unsurprisingly, Orca2—at 13 billion parameters—outperforms comparable models like LLaMA-2-Chat-13B and WizardLM-13B across all reasoning tasks, while closely competing with larger models like LLaMA-2-Chat-70B and WizardLM-70B, the latter being highly regarded as one of the best open-source models.
The Orca2 model’s foundation is LLaMA 2, illustrating that even when using the same base model as its counterparts, the cautious reasoning training method yields superior results.
Looking Ahead: Microsoft's Vision
With Orca2, we are witnessing a new era for open-source models. Microsoft’s strategy is transparent: leverage OpenAI to enhance capabilities over time with increasingly larger models, and utilize these advancements to train smaller models for extensive deployment. This approach not only contributes to a better understanding of language model training but also brings us closer to achieving the next significant milestone in AI: System 2 thought processing, characterized by deliberate and analytical thinking.
For more details, you can read the Orca 2 research paper here.