DINO-ViT: Advancing Self-Supervised Learning Techniques
Written on
Chapter 1: Understanding DINO-ViT
The journey toward achieving true artificial intelligence involves significant advancements in self-supervised learning. In previous writings, I touched on self-supervised learning and contrastive techniques, but I have yet to delve into a parallel approach that leverages the interactions between multiple networks. Currently, one of the leading training methodologies is the knowledge distillation technique known as DINO applied to vision transformers (DINO-ViT). Interestingly, the standout feature of this architecture lies not just in its classification accuracy but in its ability to extract detailed features suitable for complex tasks like part segmentation and object correspondence.
In this article, we will explore the training process of DINO-ViT, followed by a practical guide on utilizing existing libraries for tasks like part co-segmentation and establishing correspondences.
Section 1.1: What is DINO-ViT?
The term DINO stands for self-DIstillation with NO supervision. This method employs a variation of traditional knowledge distillation and integrates it with the robust architecture of vision transformers (ViT). DINO draws inspiration from the Bootstrap Your Own Latent (BYOL) technique, which we will examine in more detail in future discussions.
Subsection 1.1.1: Mechanism of Knowledge Distillation

At its core, knowledge distillation aims to enable a student network, denoted as Ps, to learn from a teacher network, Pt. In the realm of computer vision, this translates to minimizing the cross-entropy loss H between the two networks for a given image x:
Section 1.2: Extending Distillation to DINO Training
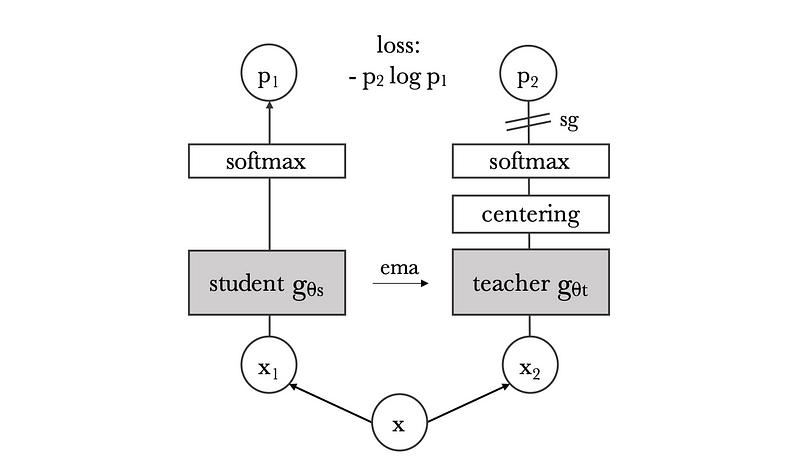
The DINO training process enhances the traditional distillation method by applying it to multiple views of a single image. Each image x is divided into two global views and several local views. While all these crops are input into the student network, only the global views are processed by the teacher network. The training aims to minimize the cross-entropy loss, encouraging the student network to learn meaningful image features by establishing both local and global correspondences.
Chapter 2: From Students to Teachers
In contrast to conventional knowledge distillation, where the teacher network's weights are predefined, DINO generates the teacher network from previous student models using a moving average technique. This process includes centering to prevent the two models from collapsing.
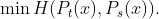
Section 2.1: Applications of DINO-ViT
DINO-ViT excels in classification tasks, a common benchmark for self-supervised methodologies. However, its remarkable capability lies in the fine-grained features it learns through self-distillation. As illustrated in the following image, DINO-ViT's attention is remarkably focused on the object's foreground, suggesting that its high accuracy in classification is just a byproduct of its rich representational power.

Section 2.2: Future Directions
Following the DINO-ViT method, a study titled "Deep ViT Features as Dense Visual Descriptors" by Amir et al. demonstrated that the dense patch-wise features obtained from DINO-ViT can tackle challenging tasks such as part co-segmentation and correspondence finding, even across different categories.

For enthusiasts, Amir et al. have made Google Colab notebooks available for their project, along with GitHub instructions for implementing these methods in larger batches. You can access the code here:
GitHub - ShirAmir/dino-vit-features: Official implementation for the paper "Deep ViT Features as Dense Visual Descriptors". We demonstrate the effectiveness…
github.com
Chapter 3: Conclusion
The path toward creating genuine AI appears to be a long one, yet self-supervised learning is a significant stride in that direction. DINO-ViT provides valuable insights into the learning processes of networks, and the potential of these learned features is a noteworthy advancement in the field of computer vision.
Thank you for reading! If you're interested in exploring more topics in computer vision and deep learning, I invite you to follow my work and subscribe for updates.
The first video titled "DINO: Emerging Properties in Self-Supervised Vision Transformers" explores the innovative aspects of DINO in the context of self-supervised learning.
The second video, "DINO -- Self-supervised ViT," dives deeper into the mechanisms and advantages of this state-of-the-art approach.